欠損値
欠損値とは
統計学における欠損値(missing value)とは、数値データの中に存在するべき値がない状態を指します。
代表的な欠損値の原因としては、
- 回答者が設問に回答しなかった場合
- 測定器具の故障等で値が計測できなかった場合
- データ入力時のミスで値が欠落した場合
などがあります。
欠損値がそのまま含まれたデータでは統計解析ができないなどの支障が生じますので、
- 欠損値とそれに伴うデータを取り除く
- 欠損値を適当な値で補完する
- 欠損値の処理方法を統計モデルに組み込む
などの対応が必要になります。
適切な欠損値の取り扱いは統計解析において重要なポイントの1つです。 欠損値には留意し、データの特性に応じた欠損値処理を行うことが求められます。
それぞれの欠損値処理手法のメリットとデメリット
- 欠損値を取り除く
- メリット
- 解析がシンプルになる
- 欠損値によるバイアスがなくなる
- デメリット
- サンプルサイズが減る
- 欠損のパターンに偏りが生じる
- 欠損値を適当な値で補完する
- メリット
- サンプルサイズを維持できる
- デメリット
- 補完方法によってはバイアスが生じる
- 解析結果の解釈が難しくなる
- 欠損値の処理方法を統計モデルに組み込む
- メリット
- 欠損のパターンを考慮できる
- サンプルサイズを維持できる
- デメリット
- モデルが複雑になる
- 計算コストが高くなる
このように、各手法には一長一短がありますので、 データの状況に合わせて適切な方法を選択する必要があります。
Reactive stat における欠損値の取り扱い
Reactive stat では、1. 欠損値を取り除く 方式としています。
それは、
- 欠損値を取り除いた完全データの解析のほうが信頼性が高く、解釈に間違いが生じにくい
- 欠損値を補完すると、解析結果にバイアスが生じ、誤った結果に繋がるリスクがある
- 論文の査読で信頼性が低い、もしくは誤った手法であるあると判断される可能性があります。
- これは、データ数が比較的少ない場合に生じやすいです。
という理由によります。
すなわち、Reactive stat は、 統計に不慣れなユーザーにも理解しやすいようにデザインされていて、 誤った結論に到達しないよう設計されている、 ということです。
Reactive stat の欠損値除去アルゴリズムは、解析に必要なデータのうち、欠損値を含むデータを取り除いて処理を行うものです。
なお、単純に欠損値を含む行を全て削除してしまうという処理も可能です。
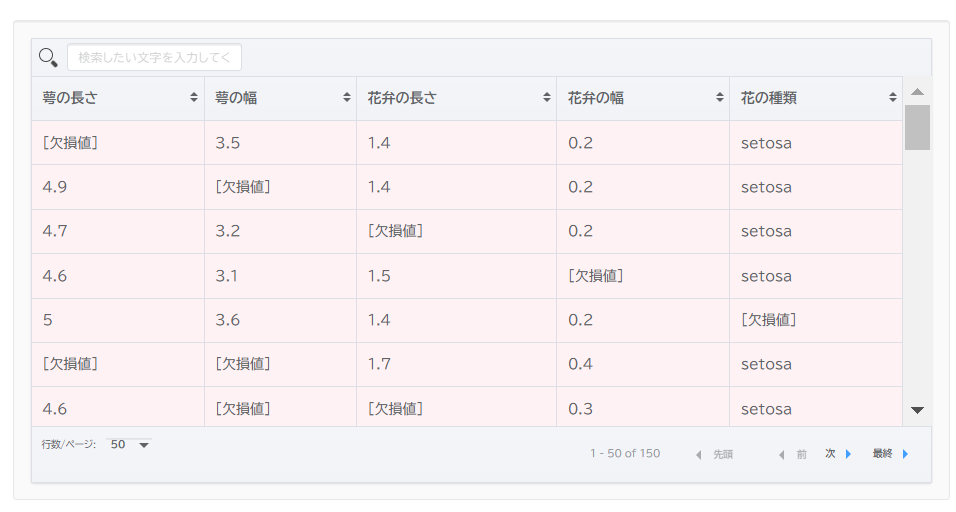
欠損値を含むデータ
欠損値を含むアヤメの花データ を使って、欠損値を含むデータを読み込んだ例を示します。

ここでは、欠損値は、“.” (半角ピリオド) で表されています。 “NaN”, “null”, “N/A”, “.”, “#NULL!” が、デフォルトの欠損値を表す文字列です。
| 文字列 | 意味 |
|---|---|
| NaN | Not a Numberの略。数値として解釈できない値。 |
| null | 空の値を意味するNULL値。 |
| N/A | Not Availableの略。利用不可能な値。 |
| . | ピリオド1つだけの値。 |
| #NULL! | Excelで用いられる#NULL!エラー。 |
これらの文字列が含まれるセルは、Reactive Stat では欠損値として扱われます。
ユーザーがCSVなどのデータを読み込む際、これらの文字や記号が現れた場合、自動的に欠損値と判断し解析から除外するよう処理されます。
読み込まれたデータは、通常は背景は白ですが、欠損値を含む行はピンク色で表示されます。また、欠損値の項目には [欠損値] が表示されます (これはあくまで表示のみで、データが “[欠損値]” に変換されたわけではありません) 。
欠損値表現のカスタマイズ


欠損値表現はカスタマイズ可能で、データの特性に応じて適切に設定できます。
「データ処理」メニューの「欠損値の設定」から、設定メニューを開くことができます。
続いて開くダイアログにて、自由に欠損値の表現を設定できます。
設定済みデータの保存


Reactive stat では、全ての設定とデータはブラウザ内に一時的に保存されるのみで、セッションの終了にて削除されてしまいます。
欠損値の設定も同様ですので、データファイルを開くたびに毎回設定することを避けるため、デフォルト以外の欠損値表現を用いている場合には、デフォルトの表現に置き換えたファイルを保存しておかれることをお勧めします。
「データ」メニューから「データをダウンロードして保存」を選択します。

保存されたCSVファイルの例です。 ここでは、欠損値には “NaN” を割り当てています。 (ピンク色の背景はわかりやすいようにしてあるだけです)
欠損値を含むデータでの統計処理
実際に欠損値を含むデータで統計処理を行った場合に、どのようになるかを具体的にお示しします。
相関と回帰を欠損値のあるデータで行ってみます。
こちらをクリックすると、欠損値のあるアヤメの花のデータを読み込んだ状態で相関と回帰のページが開きます。
 「設定」にて、X軸とY軸データのカラムを設定します。
ここでは、萼の長さと、花弁の長さを選択します。
全部で150の花のデータのうち、それぞれ5個と9個が欠損していることがわかります。
「設定」にて、X軸とY軸データのカラムを設定します。
ここでは、萼の長さと、花弁の長さを選択します。
全部で150の花のデータのうち、それぞれ5個と9個が欠損していることがわかります。
 相関を求めるには、X軸とY軸の両方のデータがそろっている必要がありますので、
Reactive stat では、そのようなデータだけを解析対象データとして利用します。
「解析対象データ」の表示を見ていただくとわかるように、それぞれ139個ずつのデータになっています。
すでに欠損値は除去されているので、欠損値の数は0になっています。
相関を求めるには、X軸とY軸の両方のデータがそろっている必要がありますので、
Reactive stat では、そのようなデータだけを解析対象データとして利用します。
「解析対象データ」の表示を見ていただくとわかるように、それぞれ139個ずつのデータになっています。
すでに欠損値は除去されているので、欠損値の数は0になっています。
すなわち、どちらか一方でも欠損値であった花のデータが11個であったので、全150個のうち、この統計処理で利用できるのは139個であったというわけです。
このように、Reactive stat では、いったん欠損値の設定を済ませてしまえば、あとは自動的にその除去処理が行われます。 そして、いくつのデータが除去されたのかが一目でわかるようになっています。
他の統計ソフトでの欠損値の扱い
R
代表的な統計処理プラットフォームである R では、高度な欠損値処理を行うことができます。
ただし、本質的にはプログラミング言語ですので、専門的な知識が必要になります。
Rには欠損値を扱うための便利な関数が用意されています。代表的なものにはna.omit()による削除処理のほか、mice、Ameliaなどの統計的な補完手法を実装したライブラリがあります。
また、線形回帰や決定木などのモデルでは、欠損値を適切に処理することで、データを削除せずにモデル構築を行うことができます。