Reactive stat のイチオシ機能
EMUYN LLC の開発チームは、少しでも理解しやすく、使いやすい統計処理アプリを目指し、議論を重ねて徹底的にユーザーインターフェースの改善に務めました。
まだまだ改善が必要と思ってはおりますが、現時点で、少し皆さんに自慢したい機能がいくつかあります。
サマリー表 (Table 1) の作成機能
 論文を書く際には必ず必要になる サマリー表 (Table 1) を簡単に用意するための機能です。
実際のところ、学会発表や小規模な論文では統計処理はこれだけで十分、という場合も多いです。
論文を書く際には必ず必要になる サマリー表 (Table 1) を簡単に用意するための機能です。
実際のところ、学会発表や小規模な論文では統計処理はこれだけで十分、という場合も多いです。
項目順を自由に並べ替えたり、p値の統計手法を指定したり、思いどおりの表が作れます。
表はそのまま表計算ソフトやプレゼンテーションソフトに貼付して利用ことができます。
いままで何時間もかかっていた作業が、大袈裟ではなく、ものの1分でできてしまいます。 ぜひお試しください。
Kaplan-Meier 生存曲線
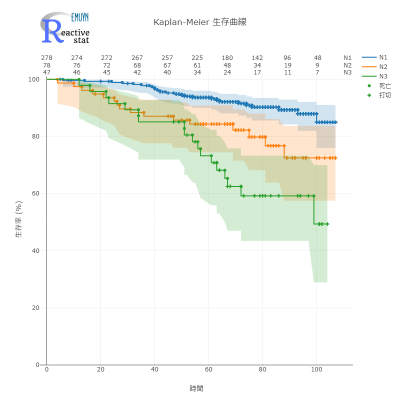
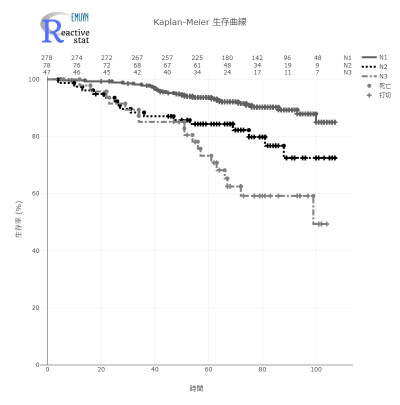
医療統計では基本なのですが、使いやすい Kaplan-Meier 生存曲線の描画ソフトが意外と見つかりません。
Reactive stat であれば、信頼区間の描画や、number at risk の表示まで、簡単に描画できます。
配色やマーカーも自在に変更できますので、希望通りの生存曲線が描けます。
難しいと思われがちな統計手法のハードルを下げました
線形混合効果モデル
比較的新しい統計手法です。 データの中に階層構造やクラスター構造がある場合や、データが時間依存性を持つ場合など、様々な応用で利用することができます。 欠損値にも強いとされています。
これを気軽につかっていただくべく、わかりやすい操作を実現しました。 ページの上段には、詳しい解説も載せてありますから、まずは試してみることをお勧めします。
傾向スコアマッチング
こちらも比較的新しい統計手法で、最近流行っています。
ランダム化されていないデータにおいて、治療群と非治療群間のバイアスを調整します。 各参加者の治療受領の確率 (傾向スコア) を推定し、スコアが似ている被験者同士をマッチングします。
すなわち、過去のデータを利用したレトロスペクティブスタディであっても、わかりやすい形で、患者背景を揃えて比較することができるようになります。 多変量解析と比べて、何が起こっているか理解しやすく、臨床の現場でも受け入れやすい結果を示すことができます。
多変量解析
多変量解析は、複数の説明変数を用いて、一つまたは複数の目的変数を分析する統計手法です。
構築したい予測モデルに応じて、まず統計手法を選択し、適切な形式のデータを用意する必要があります。 データ形式が間違っていると、分析結果の解釈が難しくなるだけでなく、誤った結論に至る可能性があります。
Reactive stat では、発想を変えて、 「どのデータから」「何が知りたいか」 を設定することで、適用可能な手法を判定し、各々について解析を行えるようにしました。
ですので、行き詰まることがありません。
分析手法として、
- 多元配置分散分析 (multi-way ANOVA; ANalysis Of VAriance)
- ロジスティック回帰モデル: Logistic Regression Model
- 共分散分析 (ANCOVA; ANalysis of COVAriance)
- 重回帰分析 (Multiple Regression)
- 多変量分散分析 (MANOVA; Multivariate ANalysis Of VAriance)
- 主成分分析 (Principal Component Analysis, PCA)
- 因子分析 (Factor Analysis)
を準備しています。
もちろん、分析手法の理解が重要であり、解析を行う上では前提となります。 そうはいっても、心配は要りません。 実際のデータで簡単にいろいろ試してみていただくことで、理解が深まるはずです。 いくつかのサンプルも用意してあります。
AI による解析結果の解説機能

R での解析を実現したあとに問題になったのは、R の出力を見てもよくわからない、という状況があるということです。
そこで、AI に手伝わせることにしました。 実際の R の出力内容を読んで、そこに出ている数字を解説してくれますから、簡単に理解を深める手助けになります。 また、発表の際にどのように述べればよいかを提案してくれます。
AI の性能はかなり向上してきましたので、理解を助け、論文や学会発表の準備に役に立ちます。 今後、さらに AI の利用を加速してゆきたいと考えています。ご期待ください。