登録データを抽出 - 複数症例のデータ抽出手順
NCD の標準機能では、各病院で入力したデータを自由にダウンロードして再利用することはできませんが、 NCD Helper の機能を用いればNCD に登録済みのデータの全自動連続一括抽出と保存が可能となります。
ここでは、NCD Helper を用いて一括抽出と保存を行う手順とを具体的にご紹介します。
NCD の登録データ検索のページにて検索した結果の一覧表に表示されているデータを一括ダウンロード(最大で一度に1000件)することができます。
NCD に登録済みのデータの全自動連続一括抽出と保存の方法を動画でもご紹介しています。ここではエクセルマクロを使用しています (約4分)
(初期に作った動画なので内容が古いです。ご了承ください)
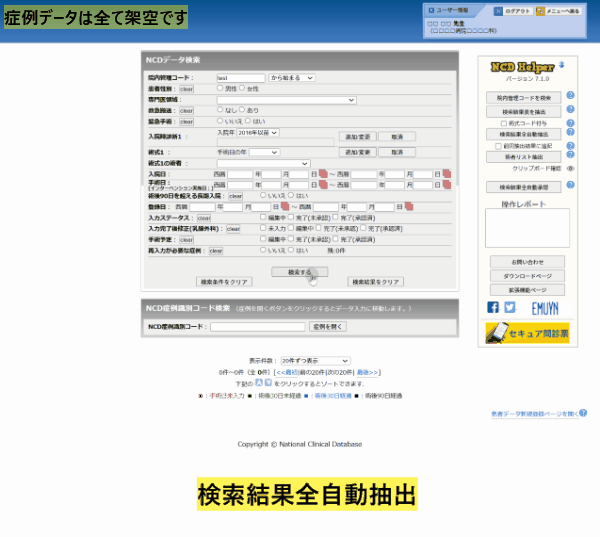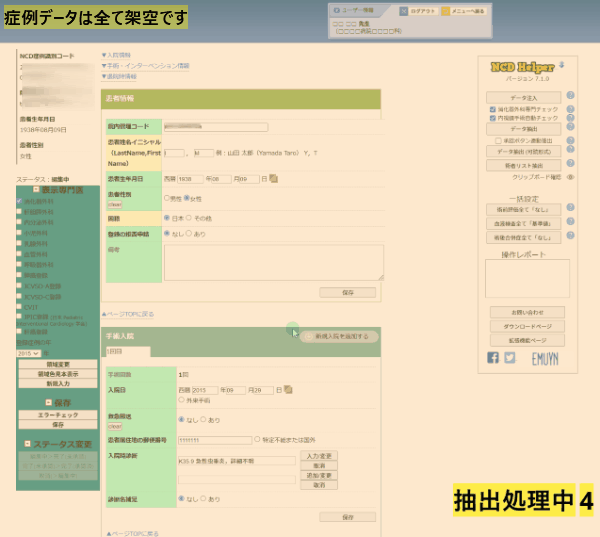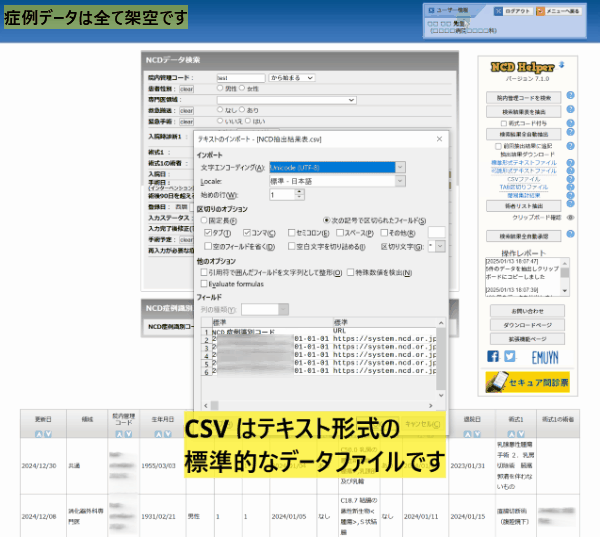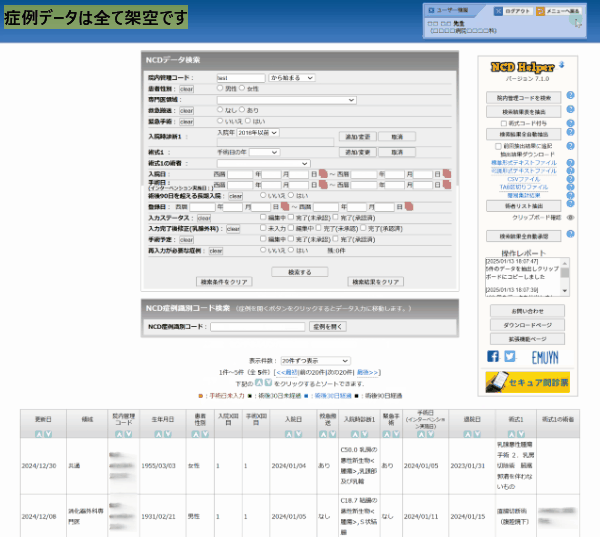
複数症例のデータ抽出は、NCD の登録データ検索のページから行います
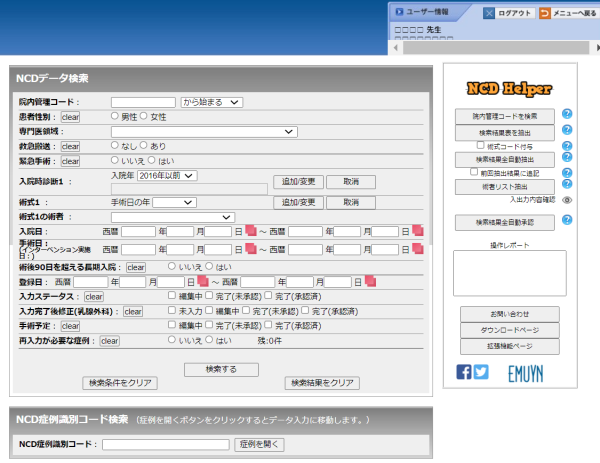
通常の手順で NCD にログインし、検索ページを開きます。
ここで、取り込みたいデータを検索してください。
検索結果の表 (下部) に表示された結果が全て取り込みの対象となります。
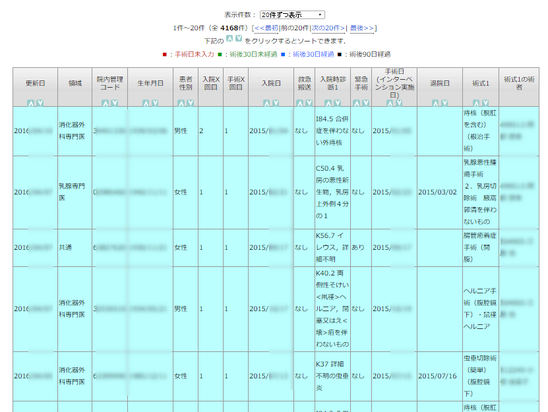
検索の結果が、例えば左のように表として出力されます。
設定により、20例~1000例が1ページに表示されます (200件以上の表示は NCD Helper による追加機能です)。
この一覧表の全症例のデータを一括取込することができます。

続いて、「検索結果全自動抽出」をクリックします。
なお、ここで「検索結果表を抽出」を押すと、一覧表に表示されている内容をダウンロードすることが可能です。
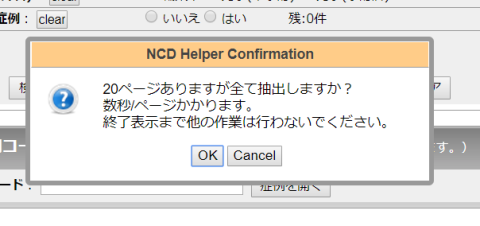
多数のページを処理し時間がかかりますので、確認のダイアログが現れます。
OK を押して処理を開始してください。
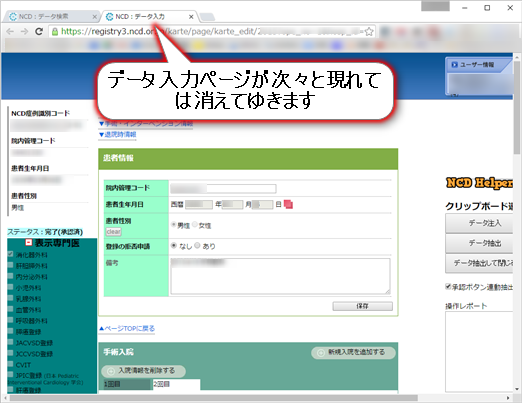
データ入力ページが次々と現れては、データが自動抽出されて消えてゆきます。
抽出されたデータはブラウザ内に蓄積されてゆきます。
この処理中には、ブラウザでほかの作業を行わないでください(別ウインドウで立ち上げたブラウザは操作可能です)。
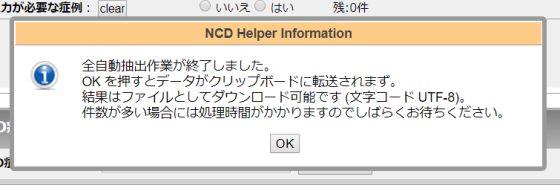
抽出処理が終了すると、このようなダイアログが現れますので、「OK」を押すと、ブラウザ内に蓄積されていた全データが、クリップボードにコピーされます。
次に示すようにエクセルマクロを用いてデータベース化したり、メモ帳などにペーストして保管して利用できます。
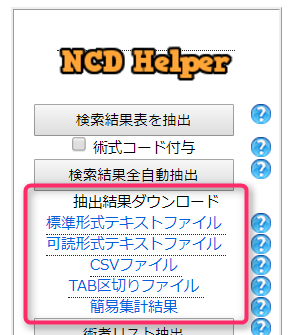
抽出結果をテキストファイルとしてダウンロードし、保存することが可能です (一括抽出作業ごとに内容が更新されますのでその都度保存してください)。
なお、抽出ファイルの文字コードは UTF-8 (BOM無し) となっております。 一部のソフトでは文字化けする場合もありますので、適宜設定を変更してください。
抽出したデータの形式については、登録データを抽出のページをご参照ください。
注意事項
PC が休止モードに入らないよう事前に設定してください
多くの件数を連続処理する場合は、PC が休止モードに入らないよう事前に設定しておくことをお勧めします。
Chrome・Edge では Keep Awake 拡張機能の導入にて容易に切り替え可能ですのでぜひお試しください。
ポップアップを許可してください
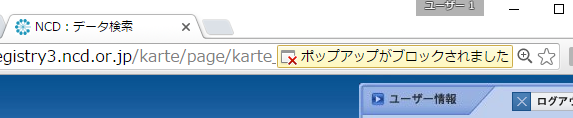
ブラウザの設定によっては、「ポップアップがブロックされました」との表示が出て操作が中断されてしまいます。
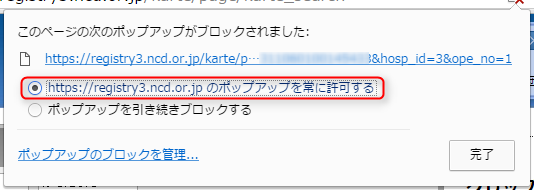
その場合は、NCD のサイトで「ポップアップを常に許可する」という設定に変更してください。
全てのデータが抽出できたか必ずご確認ください
抽出操作が終了したら、取りこぼしたデータがないか、件数を確認していただくようにお願いします。